
1. Relational Model이란?
Relational model은 Relation을 통해 구성된 모델을 일컫는다.
Relation은 Table과 Schema가 결합된 데이터구조이다. 각 열마다 Name이 구체화된 표라고 생각하면 이해가 쉽다.
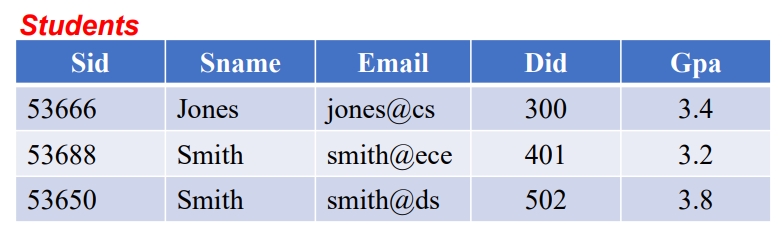
Table
Row(record, tuple)와 Column(Attribute, field)로 구성된 Instance를 지칭한다.
흔히 말하는 ‘표’ 양식이라고 이해하면 된다.
Schema
각 Column의 이름, Data Type, 그리고 Relation의 이름을 구체적으로 명시한 것을 의미한다.
- e.g., Students(Sid: integer, Sname: varchar, Email: varchar, Did: integer, Gpa: real)
[Table and Schema] ![table]()
Relational Model을 다루는 이유
Relational Model을 다루는 이유는 세계적으로 가장 많이 쓰이는 Model이기 때문이다.
IBM, Microsoft, Oracle, SAP 등등 다양한 벤더들이 이 모델을 중용하고 있다.
최근 경쟁 모델로 NoSQL, NewSQL 등이 있으나, 해당 내용은 추후 여력이 되면 다뤄보도록 하겠다.
2. Integrity Constraints (ICs)
Intergrity(무결성)이란 데이터의 정확성, 일관성을 나타냅니다.
데이터를 정확하고 일관되게 유지하는 것을 의미합니다.
ICs는 이러한 DB의 정확성, 일관성을 보장하기 위해 제약하기 위한 조건을 뜻합니다.
1) Entity Integrity (개체 무결성)
모든 테이블은 Primary Key(기본 키)로 선택된 Column 집합을 가져야 합니다.
(1) (Candidate) Key
- Relation을 구성하는 속성들 중 Tuple을 유일하게 식별할 수 있는 Column들의 부분집합
- 유일성(Uniqueness)과 최소성(irreducibility)을 만족해야 한다. – Uniqueness : 모든 레코드에서 중복값이 없는 특성 – Irreducibility : 최소한의 필드로 레코드를 유일하게 구별할 수 있는 특성
(2) Primary Key(PK) - 기본 키
기본 키는 테이블에서 특정 레코드를 구별하기 위해 후보 키 중에서 선택한 고유 식별자이다.
- Key와 마찬가지로 Unique / Irreducibile하며, NULL값을 가질 수 없다.
- 기본 키 채택 시에는 Simple하며 변동성이 적은 것, 즉 값이 자주 변경되지 않는 키로 지정하는 것이 좋다.
[PK 예시 1] ![Primary1]()

상기 테이블에서 Sid(Student ID)는 unique하지 않고 null 값을 가지기 때문에 PK가 될 수 없다.
[PK 예시 2]
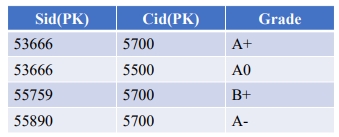
위 테이블에서 Sid와 Cid의 set은 Unique/Irreducible하며 null값을 가지지 않기 때문에 PK로 지정될 수 있다.
(3) Super Key
슈퍼키는 테이블 필드들의 부분집합으로써, Uniqueness만을 만족한다. 슈퍼키 중 irreducible한 키들이 바로 Key이다.
(4) Foreign Key (FK)
외래키는 한 테이블의 키 중에서 타른 테이블의 레코드를 유일하게 식별 할 수 있는 키를 말한다. 다른 테이블 레코드를 참조하기 위한 키이기 때문에, 참조 테이블의 기본키(Primary key)가 FK가 된다.
2) Referential Integrity (참조 무결성)
참조 무결성은 참조 대상이 존재하지 않는 외래키를 허용하지 않는 것을 일컫는다.
즉Dangling Reference를 허용하지 않는다.
아래 그림의 Did 중 502호는 참조 대상이 존재하지 않기 때문에 참조 무결성에 위배된다. 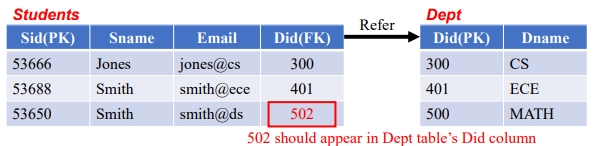
3) Domain Intergrity (도메인 무결성)
테이블에 존재하는 필드의 무결성을 보장하기 위한 것으로, Relational Database에 있는 모든 Comlumn들은 정의된 도메인(Data Type)에 따라 선언되어야 한다.
예를 들어, 아래 그림과 같이 GPA 필드에 알파벳이 입력되는 경우 도메인 무결성 위반이다. 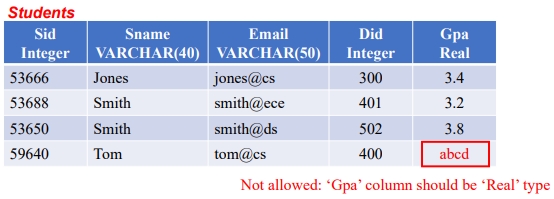
3. View
뷰는 다른 테이블을 기반으로 만들어진 가상의 테이블을 의미한다.
뷰는 실제 Row를 저장하지 않고, 논리적인 정의를 저장합니다. 가령 아래 예시와 같이 특정 조건 하의 row만을 띄우기도 합니다.
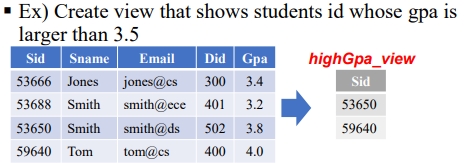
뷰를 사용하여 불필요한 기본 정보들을 숨기며, 필요한 정보만을 표시할 수 있습니다.
4. Relational Levels of Abstraction
DB에서부터 View까지는 아래 그림과 같이 추상화 단계를 정의할 수 있습니다.
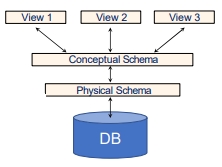
- Physical Schema : 파일이나 사용되는 Index를 묘사합니다.
– e.g. 정리되지 않은 파일로 저장된 테이블, Student id Index - Conceptual Scehma : 논리적인 구조를 정의합니다.
– e.g. Students(Sid: integer, Sname: varchar, Email: varchar, Did: integer, Gpa: real) - Views : 사용자가 어떻게 데이터를 바라보는지 정의하는 단계로써 어플리케이션의 영역입니다.
– e.g. Student_gpq_view(Sid: integer, Gpa: real)Data Independence
데이터 독립성은 하위 단계의 데이터 구조가 변경되더라도 상위 단계에 영향을 미치지 않는 속성이다.
데이터가 어떻게 구축되고 저장되는지는 어플리케이션에 아무런 영향을 미치지 않는 성질이다. - Logical data independence
– external view나 응용프로그램을 변화시키지 않고 Conceptual Schema를 변경하는 성질이다.
– e.g. 이미 존재하는 응용프로그램을 변경하지 않고 Column 등을 추가/수정/삭제할 수 있다. - Physical data Independence
– internal/physical level로부터 Conceptual level을 분리시키는 성질이다. Logical data independence보다 더욱 달성하기 어려운 성질이다.
– e.g. HDD에서 SDD로 저장 매체로 변경
– e.g. 데이터 압축 기술 변경
[Caution]
상기 내용은 서울대학교 데이터사이언스 강의에 근거하며,
무단 복제 및 스크랩을 금지합니다.